고정 헤더 영역

상세 컨텐츠
본문

제대로 파는 자바스크립트(JavaScript) - by 얄코
(https://www.inflearn.com/course/제대로-파는-자바스크립트/dashboard)
섹션 7. 배열
더보기
목차
7-1. 자바스크립트 배열의 특징과 생성
7-2. 배열의 기본 메서드들
7-3. 고차함수 메서드들
7-4. 배열의 스프레드와 디스트럭쳐링
7-5. ES14 추가기능
7-6. 중간점검 퀴즈
7-1. 자바스크립트 배열의 특징과 생성
I. 자바스크립트의 배열
배열의 형태와 동작을 흉내내는 특수 객체
한 배열에 다양한 자료형의 데이터가 들어갈 수 있음 : 연속 나열이 아님
접근이 상대적으로 느리나, 중간 요소의 추가나 제거는 빠름
특정 자료형 전용 배열도 존재 : 더 빠름

II. 배열 생성 방법들
1. 배열 리터럴
빈 요소를 포함한 배열을 생성할 수 있음
arr3에 빠진 인덱스가 있는 것을 확인할 수 있음
(인덱스 수 < length)
2. 생성자 함수
콘솔을 펼쳐서 보면 길이값(0)만 있음
인자가 숫자 하나면 길이값은 있지만 요소가 없는 배열 생성 (접근 시 undefined)
인자가 숫자가 아니거나 둘 이상이면 해당 값들로 배열 생성
3. 정적 메서드 of
인자가 하나의 숫자라도 이를 요소로 갖는 배열 생성
(비교) .of가 없는 생성자 함수: 인자가 하나의 숫자이면 그 숫자만큼의 길이를 갖는 빈 배열 생성
4. 정적 메서드 from
배열, 유사배열객체, 이터러블을 인자로 받아 배열 반환

유사배열객체: length와 인덱싱 프로퍼티를 가진 객체
일반 for문으로 순회 가능

for ... of 문은 이터러블에서만 사용 가능 (유사배열객체는 사용 불가)

배열은 이터러블
Array.from()을 사용하여 배열로 만들면 for ... of 문 사용 가능 (성능도 향상)
이후 배울 Map, Set 등의 이터러블로부터도 배열 생성 가능

Array.from은 얕은 복사 (1단계 깊이만 복사)

참조타입 요소의 내부값이 바뀔 경우
Array.from으로 복사된 배열의 내부값도 바뀜

Array.from의 두 번째 인자: 매핑 함수
- mapping: 각 요소가 특정 알고리즘을 거쳐 새 값으로 반환됨

7-2. 배열의 기본 메서드들
I. 특정 값을 반환하는 기본 메서드들
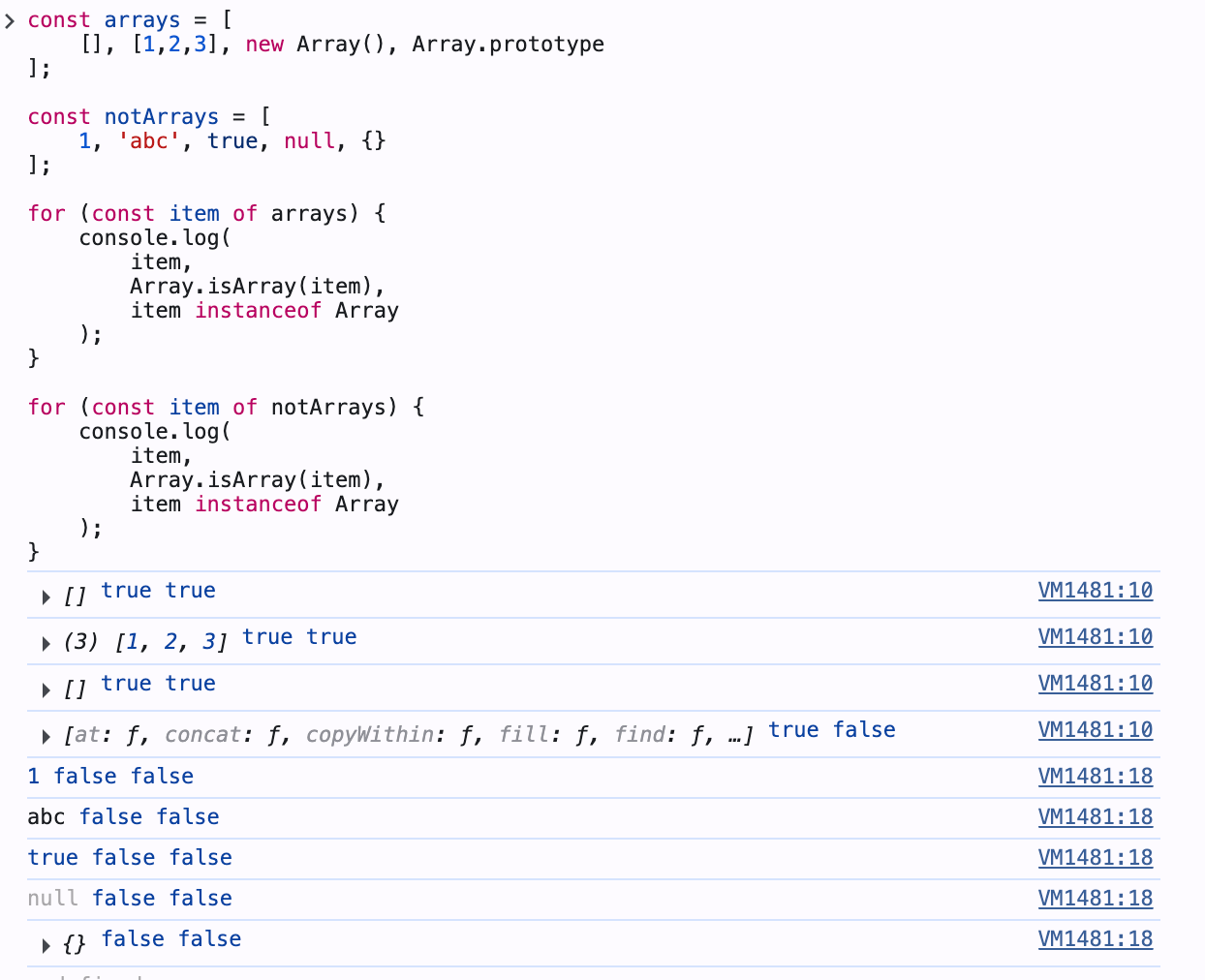
1. (정적) isArray: 배열인지 여부를 반환

split: 인수로 주어진 문자열이나 정규표현식으로 분리하여 배열을 반환
두 번째 인자로 배열의 최대 길이 지정 가능

instanceof Array와의 차이
Array.prototype만 isArray와 instanceof의 결과가 다름
(isArray: true / instanceof: false)
Array.isArray가 더 권장됨 (다른 프레임의 Array도 판별)
2. at: 주어진 인자를 인덱스로 값을 반환
음수를 사용하여 뒤에서부터 접근 가능

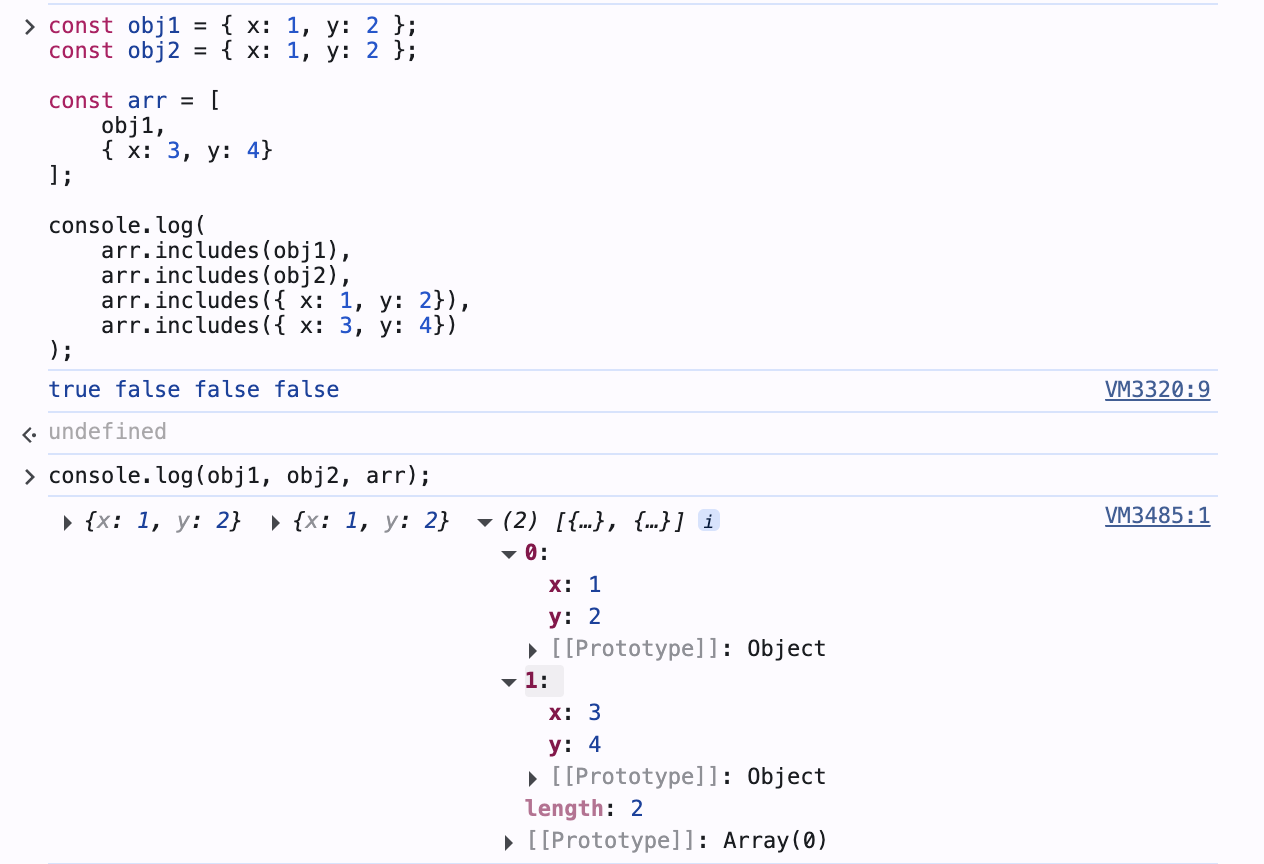
3. includes: 인자로 주어진 요소 유무 확인

참조형 데이터의 경우
arr1과 arr2는 다른 주소에 저장된 같은 내용의 객체 (내용은 같지만 둘이 참조하는 바가 다름)
{ x: 1, y: 2 } : 어떤 상수나 변수에 저장되지 않은 떠있는 객체의 값 (접근할 수 없음)
{ x: 3, y: 4 } : 위와 마찬가지로 어떤 상수나 변수에도 해당 주소가 저장되어 있지 않음
(키로 접근할 수 없음 / arr의 두 번째 인자는 단지 arr[1]의 형식(인덱스)으로만 접근 가능)
4. indexOf, lastIndexOf: 앞/뒤에서 첫 번째 값의 인덱스 반환
(없을 시 -1 반환)

5. join: 인자로 주어진 값으로 구분하여 요소들을 문자열로 연결하여 반환
인자가 없다면 쉼표 ','로 연결
string의 split과 정반대의 역할
array의 값이 변경되는 것은 아님
null과 undefined -> 공백(아무것도 출력되지 않음)
객체 -> [object Object]
배열 -> 쉼표로 구분하여 값만 출력

split과 join을 사용하여 replaceAll의 역할을 대신할 수 있음

이전에 다룬 4-3강 예제를 join을 사용하여 간단하게 작성할 수 있음

II. 배열을 변경하는 기본 메서드들
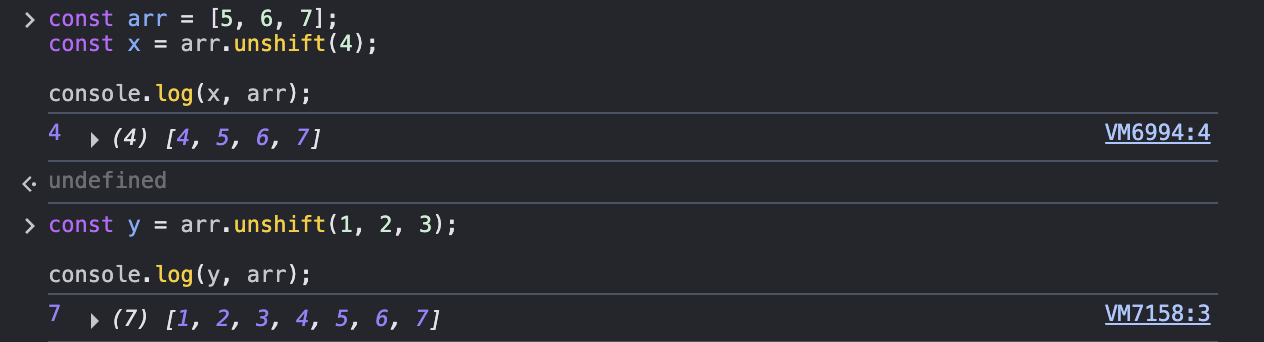
1. push, unshift: 배열에 값을 추가
수정된 배열의 길이를 반환
부수효과: 원본 배열을 변경
push보다 unshift가 더 느림 (이후 요소들을 밀어내야 하므로)
a. push: 값을 배열의 뒤에 추가하고 최종 길이를 반환함

b. unshift: 값을 배열의 앞에 추가하고 최종 길이를 반환함
2. pop, shift: 배열에서 값을 제거하여 반환
제거된 값을 반환
pop보다 shift가 더 느림 (이후 요소들을 당겨야 하므로)
a. pop: 값을 뒤에서 제거하여 반환


b. shift: 값을 앞에서 제거하여 반환


3. splice: 원하는 위치에 요소(들)을 추가 및 삭제
2개 이상의 인자를 받음
- start: 배열 변경을 시작할 위치
- deleteCount: 제거할 요소의 개수
- item(s): 추가할 하나 이상의 요소

잘라낸 요소는 반환하고, 남은 부분은 원래 배열에 그대로 남음
예를 들어, .splice(4, 3)을 실행하면
- 배열의 4번 인덱스부터 3개를 삭제
- 삭제된 요소들을 반환
- 원본 배열에서 해당 요소들이 제거됨
배열의 delete: empty 값을 남김
-> 배열의 값을 삭제하고 싶으면 splice 사용

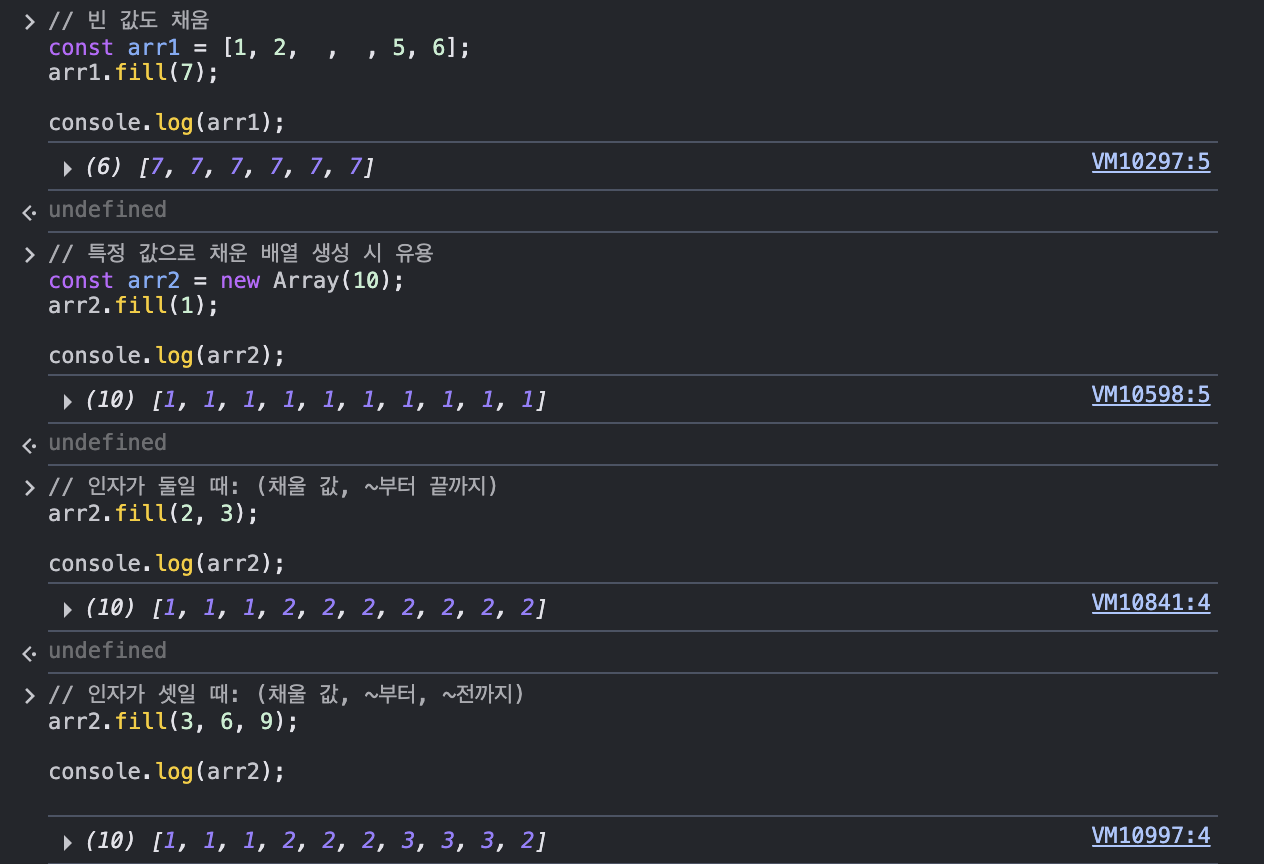
4. fill: 배열을 특정 값으로 채움
1개 이상의 인자를 받음
- 첫 번째 인자: 채울 특정 값
- 두 번째 인자: 두 번째 인자 위치부터 채움 (없으면 전체를 특정 값으로 채움)
- 세 번째 인자: 세 번째 인자 위치 전까지 채움 (없으면 시작 위치부터 끝까지 특정 값으로 채움)
5. reverse: 배열의 순서를 뒤집음
메서드 사용 시 뒤집힌 배열을 반환하고, 원본 배열도 뒤집힘
반환된 배열은 원본과 같은 배열을 참조 (복사가 아님)

III. 새 배열을 반환하는 기본 메서드들
원본 배열을 수정하지 않음
얕은 복사본
1. concat: 배열에 다른 배열이나 값을 이어붙인 결과를 반환
해당 배열 뒤로 하나 이상 주어진 배열이나 값을 이어붙인 결과를 반환

2. slice: 인자로 주어진 범주의 값을 잘라 반환
1개 이상의 인자를 받음
- begin: 시작 위치
- end: 종료 위치 (이전까지 반환, 없으면 끝까지 반환)

3. flat: 인자로 주어진 깊이만큼 배열을 펼쳐 반환
flat: 평평하게 한다는 의미

위의 메서드들은 얕은 복사 (concat(), slice(), flat())
원시값과 참조값 비교
원본을 변경했을 때 복사본의 원시값(1)은 변하지 않고, 참조값(2->20, 3->30)만 함께 변경됨
(얕은 복사를 하면 내부 참조값이 동일하게 유지되어, 원본을 수정하면 복사본도 영향을 받음)

7-3. 고차함수 메서드들
배열의 고차함수 higher order function 메서드
다른 함수(콜백 함수 callback function)를 인자로 받는 함수
함수형 프로그래밍: 변수 사용 없이 순회 작업들을 코딩
1. forEach: 각 요소를 인자로 콜백함수 실행
for문의 좋은 대체제
단점: 예외를 던지지 않으면 종료할 수 없음 (break, continue 사용 불가)
인자들
- 콜백함수 (인자로 현재 값, 현재 값의 인덱스, 해당 배열을 받음)
- thisArg (this 섹션에서 다룸)
콜백함수의 인자가 하나인 경우: 현재 값

인자를 따로 지정해주지 않으면 현재 값, 인덱스, 배열 세 값에 대해 각각 함수를 실행함

콜백함수의 인자가 둘인 경우: 현재 값, 인덱스


콜백함수의 인자가 셋인 경우: 현재 값, 인덱스, 배열
(세 번째 인자는 원본 배열의 참조 -> 원본 배열이 수정됨)

2. map: 각 요소를 주어진 콜백함수로 처리한 새 배열 반환
인자들
- 콜백함수 (인자로 현재 값, 현재 값의 인덱스, 해당 배열을 받음)
- thisArg



* 디스트럭쳐링 (섹션 5)


3. find, findLast, findIndex, findLastIndex: 주어진 기준으로 검색
- find: 콜백함수에 인자로 넣었을 때 true 반환하는 첫 번째 값 반환
- findLast: 콜백함수에 인자로 넣었을 때 true 반환하는 마지막 값 반환
- findIndex: 콜백함수에 인자로 넣었을 때 true 반환하는 첫 번째 값의 인덱스 반환
- findLastIndex: 콜백함수에 인자로 넣었을 때 true 반환하는 마지막 값의 인덱스 반환
공통 인자들
- 콜백함수 (인자로 현재 값, 현재 값의 인덱스, 해당 배열을 받음)
- thisArg


4. some, every: 어떤/모든 요소가 기준을 충족하는지 확인
- some: 콜백함수에 인자로 넣은 요소들 중 하나라도 true를 반환하는가 여부 반환
- every: 콜백함수에 인자로 넣은 모든 요소가 true를 반환하는가 여부 반환
인자들
- 콜백함수 (인자로 현재 값, 현재 값의 인덱스, 해당 배열을 받음)
- thisArg


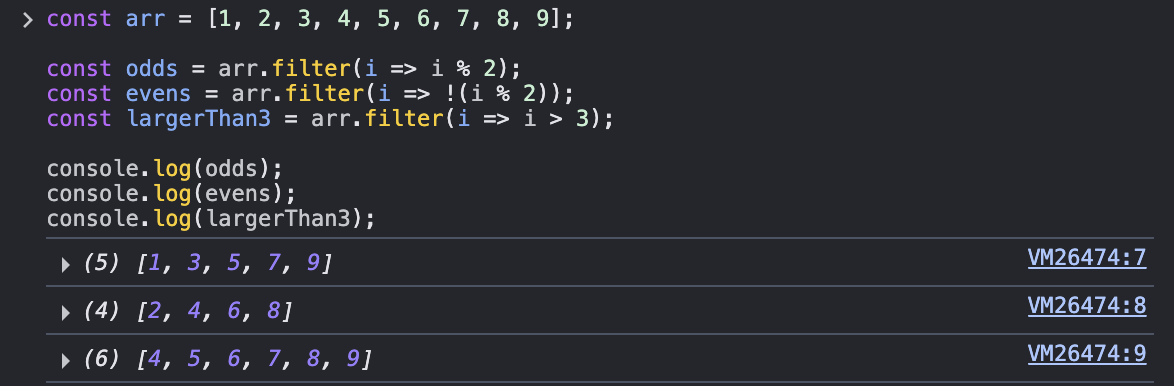
5. filter: 주어진 기준을 충족하는 요소들로 새 배열을 만들어 반환
원본 배열을 수정하지 않음
인자들
- 콜백함수 (인자로 현재 값, 현재 값의 인덱스, 해당 배열을 받음)
- thisArg

6. reduce, reduceRight: 주어진 콜백함수에 따라 값들을 접어 나감
인자들
- 콜백함수 (인수로 초기화 값/이전 반환 값, 현재 값, 현재 인덱스, 해당 배열을 받음)
- 초기화 값 (없으면 첫 번째 값)
초기화 값이 없을 때는 첫 번째와 두 번째 값부터
*console.log()는 과정을 확인하기 위한 코드. 최종 결과 return 값(45)

초기화 값이 있을 때 (인덱스가 0부터 시작함)




reduce vs. reduceRight
reduce(callback[, initialValue])
- 왼쪽에서 오른쪽으로 배열을 순회하며 누적 값을 계산함
- 첫 번째 요소부터 시작하여 다음 요소로 진행함
reduceRight(callback[, initialValue])
- 오른쪽에서 왼쪽으로 배열을 순회하며 누적 값을 계산함
- 마지막 요소부터 시작하여 이전 요소로 진행함
- reduceRight는 인덱스도 거꾸로 진행됨

배열 메서드와 체이닝 활용
- 다음 코드를 배열 메서드와 체이닝 없이 짠다면 중간 과정을 저장하기 위한 변수 또는 내용이 바뀌는 참조형 데이터들이 필요함
- 함수형 프로그래밍: 변수들을 코드에서 감추어 부수효과로 인한 문제 방지

7. sort: 배열을 (주어진 기준대로) 정렬
배열 자체의 순서를 바꾸고 해당 배열을 반환함 (원본 수정)
기본적으로 문자열 기준으로 정렬함
인자들
- 콜백함수 (앞의 값과 뒤의 값을 인자로 받음 / 생략 가능)
인자가 없으면 오름차순 정렬


숫자에 sort() 적용 시 기대와 다른 결과가 나옴
숫자를 문자열로 암묵적 변환하여 오름차순 정렬(앞자리부터 순서대로 비교함(사전 순) / ex. 10 < 2)

정확한 정렬을 위해 콜백 함수 사용하기
두 인자 a와 b(인접한 두 요소)를 기준으로
- 반환 값이 0보다 크면 b를 앞으로 (순서 뒤집기)
- 반환 값이 0이면 순서 유지 (ECMAScript 표준은 아니므로 환경마다 다를 수 있음)
- 반환 값이 0보다 작으면 a를 앞으로 (순서 유지)
(주의) 브라우저마다 동작 디테일이 다름
인접한 앞의 것과 뒤의 것을 콜백함수의 첫 번째와 두 번째 인자(a, b) 중 어느 것으로 받아오는지가 브라우저마다 다름
Chrome vs. Firefox
| Chrome | Firefox |
| TimeSort 알고리즘 사용 (merge sort + insertion sort 조합) | Merge Sort 알고리즘 사용 |
| 안정 정렬(Stable Sort) : 기존 순서 유지 | 최신 버전에서는 안정 정렬 보장 (특정 조건에서 크롬과 다르게 정렬) |
sort() 비교 함수의 동작 방식
sort()는 비교 함수 (a, b) => 결과값을 사용하여 배열을 정렬함
a - b < 0 : a가 앞에 옴
a - b > 0 : b가 앞에 옴
a - b = 0 : 순서 변경 없음
하지만, return -1; 사용 시 브라우저마다 다르게 해석할 수 있음
Chrome:
모든 요소가 -1을 반환하면 정렬 기준이 모호해짐
TimSort는 내부적으로 최적화를 수행하며, 그 과정에서 일부 요소들의 상대적인 위치가 유지되지 않을 수도 있음
결과적으로 원래 순서와 달라질 가능성이 있음
Firefox:
MergeSort도 비교 기반 정렬이지만 정렬 과정에서 항상 두 개의 부분 배열을 합치면서 정렬을 수행함
모든 비교에서 a를 b 앞에 두라는 것을 이미 정렬된 상태로 간주할 수 있음
결과적으로 원래 순서가 그대로 유지될 가능성이 높음


return 1;의 경우 Chrome이 순서 유지, Firefox가 반대로 정렬될 가능성이 높음




return -1; 과 return 1; 은 예측할 수 없는 동작을 유발할 수 있음
따라서 항상 정확한 비교식을 사용해야 함
숫자 정렬 (정확한 비교식)
오름차순 정렬
numbers.sort((a, b) => a - b);a - b가 음수(a<b)면 a가 먼저 오고, 양수(a>b)면 b가 먼저 옴
즉, 작은 값이 앞에 오도록 정렬됨 (오름차순)
내림차순 정렬
numbers.sort((a, b) => b - a);b - a가 음수(a>b)면 a가 먼저 오고, 양수(a<b)면 b가 먼저 옴
즉, 큰 값이 앞에 오도록 정렬됨 (내림차순)
숫자 정렬 정리
오름차순: arr.sort((a, b) => a - b);
내림차순: arr.sort((a, b) => b - a);

객체 배열 정렬
객체 배열을 특정 키(age)를 기준으로 정렬 가능
const users = [
{ name: "Charlie", age: 30 },
{ name: "Alice", age: 25 },
{ name: "Bob", age: 28 }
];
users.sort((a, b) => a.age - b.age);
숫자가 아닐 경우 직접 반환값을 명시
arr.sort((a, b) => a > b ? 1 : -1)a(Z)가 b(A)보다 크면 1 → b(A)가 앞으로 옴
a(A)가 b(Z)보다 작으면 -1 → a(A)가 앞으로 옴
즉, 사전 순으로 정렬됨

반대로 정렬하기 (a < b)
arr.sort((a, b) => a < b ? 1 : -1)
활용: 둘 이상의 기준 사용

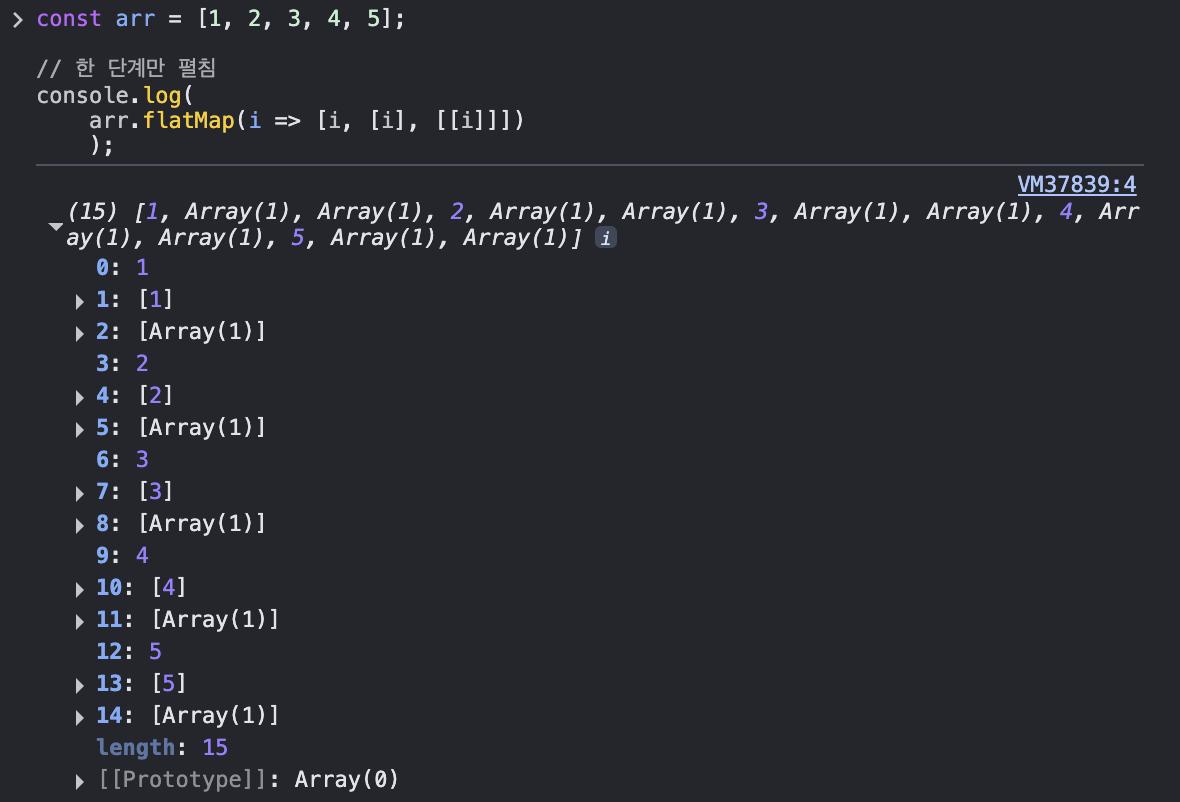
7. flatMap: map한 후 flat (매핑해서 펼침)
인자들
- 콜백함수 (인자로 현재 값, 현재 값의 인덱스, 해당 배열을 받음)
- thisArg

flatMap은 한 단계만 펼침

7-4. 배열의 스프레드와 디스트럭쳐링
I. 스프레드 spread
1. 기본 문법

2. 활용
a. 배열을 다수의 인자들로 펼침

spread를 활용하면 Math.max와 Math.min을 통해 최댓값과 최솟값을 구할 수 있음
(배열을 넣으면 NaN 출력)



b. concat보다 가독성있는 배열 결합
동일한 결과 출력

c. 배열의 얕은 복사
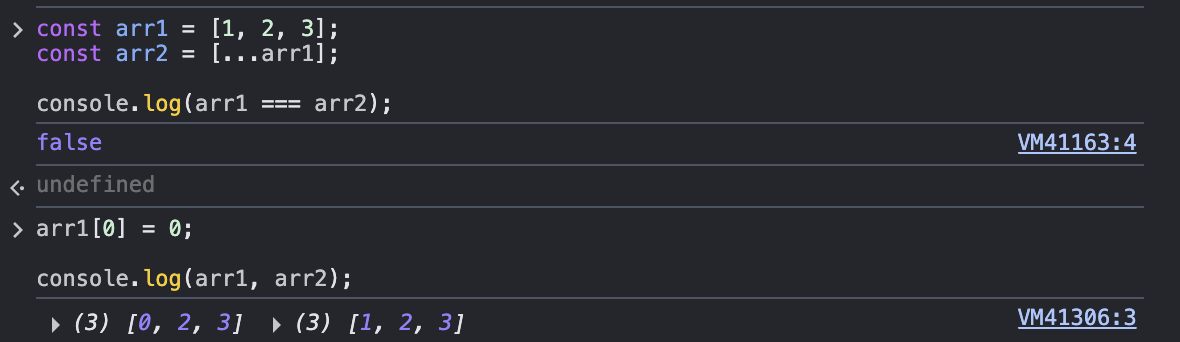
깊은 복사는 되지 않음

d. push, unshift 대신 사용
가독성 향상
배열이 든 변수의 참조값이 변할 필요가 있는 경우 (SPA 등)

(참고) React 같은 SPA(싱글 페이지 애플리케이션)에서 상태(State) 관리 시 필요
React에서는 상태가 직접 변경되면 변화를 감지하지 못함. 새로운 참조값을 가진 배열을 할당해야 변화를 감지할 수 있음
즉, 배열의 참조값이 바뀌어야 React 같은 라이브러리가 상태 변경을 감지하고 UI를 업데이트할 수 있기 때문에 spread 문법을 활용함
e. 원본 배열을 유지한 채 일정부분만 연결하여 복사
(참고) splice는 원본 배열을 변경
slice와 spread를 사용하여 원본 배열 유지

다른 방법 (.filter 사용)

(참고) filter((_, i) => ...)에서 _의 의미
_는 매개변수 자리에 있지만 사용되지 않는 값을 무시하는 의미로 사용됨
filter((value, index) => 조건) 형식이지만, 요소 값은 필요 없고 인덱스(i)만 사용하므로 첫 번째 매개변수(value)는 _로 표기한 것임
JavaScript에서는 _는 일반 변수명처럼 동작하지만, 보통 "사용하지 않는 값"을 나타낼 때 사용됨
II. 디스트럭처링 destructuring
1. 문법

일부만 가져오는 것도 가능

기본값 설정 (기본값보다 할당값이 우선)

나머지 변수 사용 가능

2. 활용




7-5. ES14 추가기능
1. 부작용(원본 배열 수정)을 제거한 메서드들
원본 배열의 내용을 수정하지 않음
함수형 패러다임의 기조를 따름
a. toSorted: 정렬된 결과를 반환

sort(): 원본 배열도 정렬됨
toSorted(): 원본 배열은 변화 없음
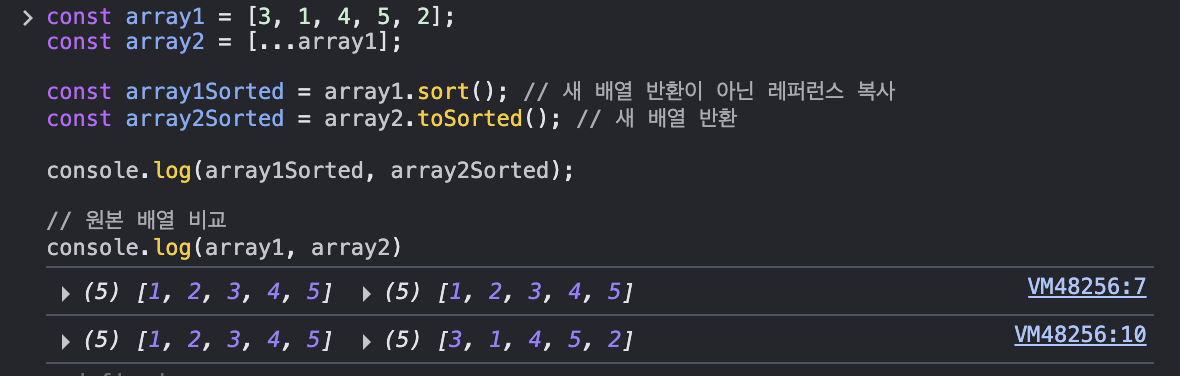
push() 결과 비교
sort(): array1와 array1Sorted는 같은 배열임! (array1Sorted에 push하면 array1에도 반영됨)
toSorted(): array2와 array2Sorted는 다른 배열

ES14 이전에 사용한 방법
toSorted() 이전에는 원본 배열이 수정되는 것을 피하기 위해 다음과 같이 spread를 이용함
array3.toSorted와 같은 결과

toSorted()도 고차함수이므로 콜백함수를 받을 수 있음

b. toReversed: 뒤집힌 결과를 반환
reverse(): 원본 배열도 뒤집힘
toReversed(): 원본 배열은 변화 없음

push() 결과 비교
reverse(): array1와 array1Reversed는 같은 배열임! (array1Reversed에 push하면 array1에도 반영됨)
toReversed(): array2와 array2Reversed는 다른 배열

c. toSpliced: 잘린 결과를 반환

splice(): 잘라낸 부분 반환 (원본: 잘라내고 남은 부분)
toSpliced(): 잘라내고 남은 부분 반환 (원본 배열은 변화 없음)

추가할 하나 이상의 요소(item(s))를 인자로 받을 수 있음

2. 뒤에서부터 찾는 메서드들
a. findLast: 주어진 조건에 해당하는 마지막(뒤에서 첫 번째) 요소 반환
b. findLastIndex: 주어진 조건에 해당하는 마지막(뒤에서 첫 번째) 요소의 인덱스 반환

ES14 이전에 사용한 방법
findLast()/findLastIndex() 이전에는 reverse()를 사용하여 뒤에서부터 찾음
원본 배열이 수정되는 것을 피하기 위해 다음과 같이 spread를 함께 이용함
*lastIndexOf: 뒤에서 첫 번째 값의 인덱스 반환

3. 부분적으로 수정한 배열을 반환
with: 첫 번째 인자로 주어진 인덱스의 값을 두 번째 인자로 주어진 값으로 수정한 새 배열 반환
아래 방법은 원본 배열이 수정됨

with 사용
원본 배열 수정 없이 4번째 요소를 '넷'으로 바꾼 배열을 반환

with를 여러 번 사용할 수 있음

다른 방법. slice와 spread 사용

7-6. 중간점검 퀴즈
1. 배열의 메소드들을 활용해서, 홀수만 추려내어 10을 곱한 뒤 각각 출력하는 코드를 작성해보세요.
const numbers = [1, 2, 3, 4, 5];예상 답:
console.log(
numbers.filter(i => (i % 2 === 1))
.map(i => i * 10)
);
정답:
numbers
.filter(n => n % 2) // 홀수: 1 (true) / 짝수: 0 (false) 이용
.map(n => n * 10)
.forEach(n => console.log(n)); // 각각 출력이므로 forEach 문 사용
2. reduce를 사용해서 최대값을 구하는 코드를 작성해보세요.
const numbers = [1, 3, 2, 5, 4];예상 답:
console.log(numbers.reduce((a, b) => a > b ? a : b));
정답:
const max = numbers.reduce(
(acc, cur) => (cur > acc ? cur : acc)
);
console.log(max);
3. 18세 이상의 사용자 이름을 쉼표로 구분한 대문자로 출력하는 코드를 작성해보세요.
const users = [
{ name: 'Alice', age: 17 },
{ name: 'Bob', age: 23 },
{ name: 'Charlie', age: 16 },
{ name: 'David', age: 30 },
{ name: 'Eddie', age: 28 }
];예상 답:
console.log(
users.filter(({age}) => age >= 18)
.map(({name}) => name)
.join(', ')
.toUpperCase()
);
정답:
console.log(
users
.filter(({age}) => age >= 18)
.map(({name}) => name.toUpperCase())
.join(', ')
);
4. 사용자가 직업별로 몇 명이 있는지 객체로 반환하는 코드를 작성해보세요.
목표 결과: {developer: 3, designer: 1, manager: 1}
const users = [
{ name: 'Alice', job: 'developer' },
{ name: 'Bob', job: 'designer' },
{ name: 'Charlie', job: 'developer' },
{ name: 'David', job: 'manager' },
{ name: 'Eve', job: 'developer' }
];예상 답:
const jobCount = { developer:'', designer:'', manager:'' };
jobCount.developer = users
.filter(({job}) => job === 'developer')
.length;
jobCount.designer = users
.filter(({job}) => job === 'designer')
.length;
jobCount.manager = users
.filter(({job}) => job === 'manager')
.length;
console.log(jobCount);
const jobCount = { developer:'', designer:'', manager:'' };
for (const key in jobCount) { // for...in : 객체의 키 순회
jobCount[key] = users
.filter(({job}) => job === key)
.length;
}
console.log(jobCount);
정답:
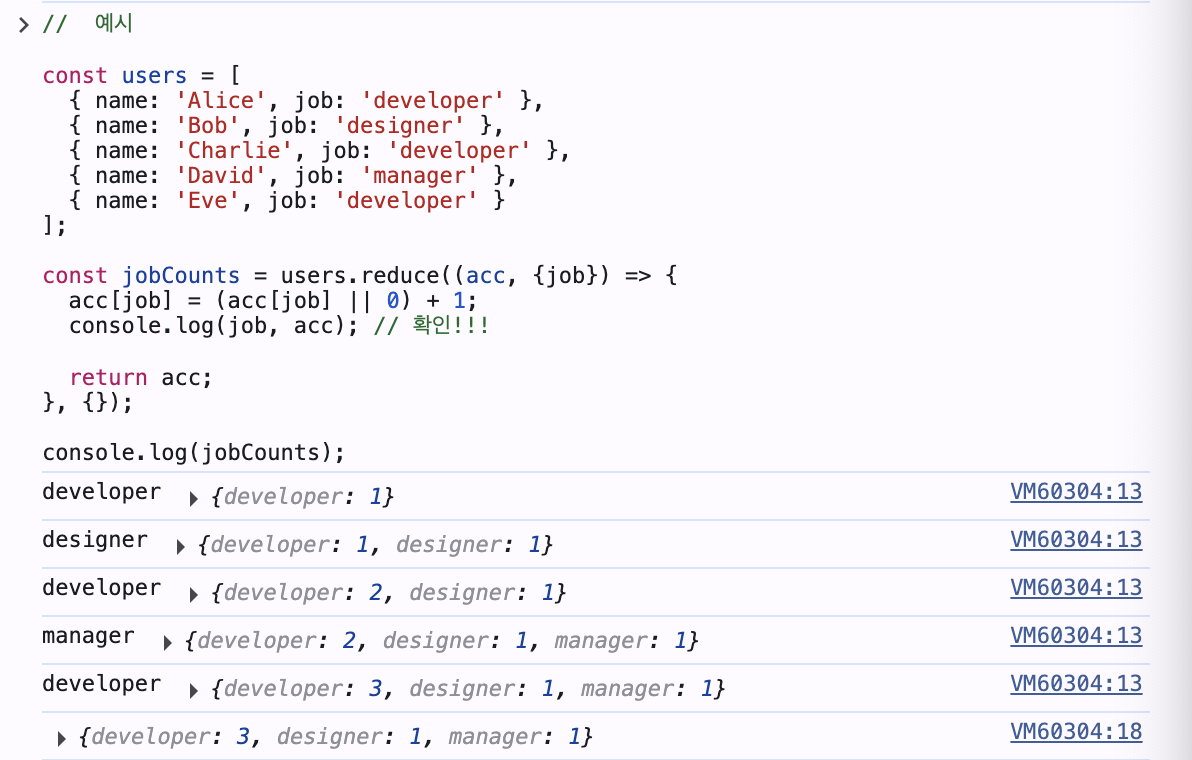
const jobCounts = users.reduce((acc, {job}) => {
acc[job] = (acc[job] || 0) + 1; // acc[job]이 존재하면 +1 증가 || 존재하지 않으면 0으로 초기화 후 +1
return acc;
}, {}); // {} → 초기 객체 (acc)
console.log(jobCounts);
(참고) reduce: 주어진 콜백함수에 따라 값들을 접어 나감
인자들
- 콜백함수 (인수로 초기화 값/이전 반환 값, 현재 값, 현재 인덱스, 해당 배열을 받음)
- 초기화 값 (없으면 첫 번째 값)
작동 과정 확인
5. 아래 배열들 중 가장 큰 수를 출력하는 가장 간결한 코드를 작성해보세요.
const x = [12, 37, 5, 42, 19];
const y = [28, 4, 33, 21, 50];
const z = [47, 13, 9, 36, 22];예상 답:
console.log( Math.max(...x, ...y, ...z) );
정답:
console.log( Math.max(...x, ...y, ...z) );
FIN.
728x90
'[SW] > JavaScript (2025)' 카테고리의 다른 글
| [자바스크립트] 섹션 9. 추가 자료형들 (0) | 2025.04.08 |
|---|---|
| [자바스크립트] 섹션 8. 객체 깊게 다루기 (0) | 2025.04.08 |
| [자바스크립트] 섹션 6. 주요 빌트인 객체 (1) | 2025.01.26 |
| [자바스크립트] 섹션 5. 객체와 클래스 (0) | 2025.01.18 |
| [자바스크립트] 섹션 4. 함수 (1) | 2025.01.18 |





댓글 영역